予選の問題作成を担当したDeNAのkarupaneruraです。
予選に参加した皆様、お疲れ様でした。 楽しんで頂けましたでしょうか。
お陰様で大きなトラブルもなく無事に予選を終えることができました。 参加者の皆様をはじめとした皆さんのご協力がなければ成し得ないことでした。 ご協力いただいた皆様、ありがとうございました。
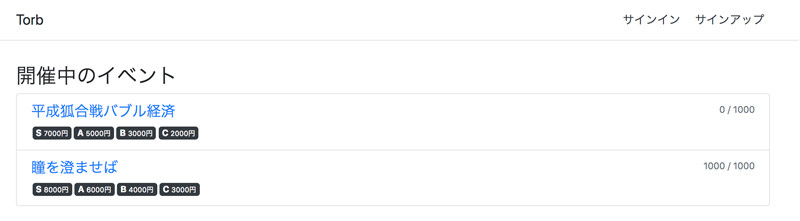
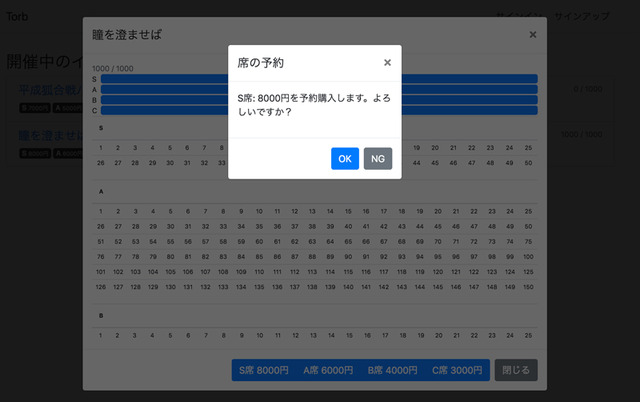
ユーザーを作成、またはログインを行うと座席を予約することができます。 座席は抽選で決まる仕組みになっており、ランダムに決まった座席が即座に分かるようになっています。 埋まっている座席は黒く塗りつぶされ、自分の獲得した座席は緑色の字で表示されています。 また、自分の座席をクリックするとキャンセルを行うことができます。
マイページでは自分の最近予約(orキャンセル)した席を5件、最近予約(orキャンセル)したイベントを5件、そして予約総額を表示していました。 また、未ログイン時は予約/キャンセル/マイページの閲覧はできませんが、座席の空き状況を確認することができました。
管理画面もあります。 管理画面は一般向けの画面とは異なりログインするまでどのような情報も見ることはできません。 ログインすると、一般向けに公開していないものも含めてすべてのイベントを表示できます。 座席の予約状況も同様に閲覧することができるほか、イベントの状態を変更することができます。 イベントの状態は公開/非公開/終了の3パターン存在し、公開/非公開は何回でも変更することができますが、終了にすると二度と状態を変更できません。
そして、管理画面にはレポート機能もあります。 全体/イベント毎のチケットの購買履歴をCSVとしてダウンロードすることができます。
実装としては、フロントエンドはvue.jsを用いたSPA風の構成になっており、ラウンドトリップを減らすため初期レンダリングに利用するデータだけJSONでHTMLに埋め込んで、 あとは基本的にAPI経由でデータを取得するという仕組みになっています。(Instagramなどで行われています)
バックエンドは3台のCentOSのサーバー(2core/1GB)で、初期状態では3台起動して1台だけですべてのリクエストを処理していました。 データベースはCentOS7の標準パッケージのMariaDB 5.5、リクエストはHTTPでtcp/80にh2o 2.2.5で受けて、Perlの参照実装にリバースプロキシして渡していました。
初期データとしては101人の管理者アカウント、18個のイベント、5000人のユーザーアカウント、キャンセルを含む予約データ約20万件が入っていました。
問題のコード群は github.com/isucon/isucon8-qualifyで公開しています。
今回は実際のWebアプリケーション運用の現場で起きる実際の問題解決に近いものを課題にしたいと考えていました。 具体的には以下のようなポイントを押さえることを目指しました。(事前のディスカッションの議事録から抜粋)
これらのポイントを押さえるため、レースコンディション問題を題材に大量の並行トランザクション地獄を作ると、自分たちが実際に向き合うことの多い課題に近く良いのではないか? 過去のISUCON2がこれに近かったし過去問のリバイバルというのは新しいし、面白いのではないか?ということでこういう問題になりました。
ということで、今回は一芸では突破できない様々なハードルを用意しましたが、メインテーマは強いて言えば「大量の並行トランザクションによるロック地獄をどう解決するか?」でした。 様々な問題の解決が要求されるので、これを突破できたチームは本当にすごいと思います。おめでとうございます。
悪いDB設計 これに初期データ量とマシンスペックや台数の制約、API仕様が組み合わさり、今回のような難易度の問題をつくることができました。 ちなみに、参照実装(問題)の開発には今回は自分が一番慣れているPerlを利用しました。他言語の実装はPerl実装を参考に移植されたものです。 さらに余談ですが、感想戦のgame master実装もPerlでした。
しかし、開催後に気付いたことですが、参照実装にはいくつかバグが残ってしまっていました。
予約エンドポイントの予約成功するまでの無限ループはキャンセル時刻をテーブルに保存する仕様を入れる前の実装の名残がうっかりそのまま残ってしまったものでした。 また、その歳にトランザクションの範囲も直しそこねていて、それによってレースコンディション問題が低確率で発生するようになっていました。パフォーマンスが上がるとこれがエラーとして出て来るようになってしまったと思います。
Discordの感想部屋で話題になっていた
また、Go実装においてはレポートの生成処理で消費するメモリ量が、意図せず他言語における実装に対して有意に少ない実装になってしまっていました。 要因は大きく3つあります。
その他、言語によっては
これらの参照実装の不手際で不要な混乱を招いてしまい本当に申し訳ありませんでした。運悪くこれらに躓いてしまったチームもあったと思います。 ただ、競技としては皆さん同じ条件の下で競っていますので、参照実装のバグも込みで時間内に問題を解決できたかどうかが結果ということでご容赦頂ければと思います。
さて、皆さんのブログやGithubのコードを軽くざっと眺めさせてもらいました。 最初のボトルネックがうまく特定できたチームとそうでないチームが半々くらいでしょうか。
上位陣のチームはやはり皆さん
特に、惜しかったチームには改修のバグ修正に手間取ったチームが多かったように見えました。
たとえば、
こういった問題をすばやく解決するためにはデバッグ(QA)能力も重要です。 少なくとも1分以上は掛かってしまうベンチマークをわざわざ待たずに、デバッガを仕込んだり変数ダンプなどでデバッグを手早く行っていくという能力も重要な要素でした。 勝ち抜いたチームはバグで躓くことはありつつも、ある程度しっかりとバグを取ることができていたようです。
さすがに競技中にテストを書くチームはなかったようですが、予約→取得→キャンセル→取得といった流れくらいはシュッとテストできるようにしておくと開発スピードが上がったかもしれません。 ほうじ茶ラテ部はcurlなどでシュッと動作確認出来るようにしておいたようです。これは良いプラクティスだと思います。
また、チームによっては複数台展開を切ってほとんどメモリに載せてレスポンスをさばく戦略を取ったチームもあったようです。 さらに、この問題は(結果的に時間内にDBネックを脱出しきったチームは殆ど無かったようですが)DBネックを解消しきるとアプリケーションのCPUにボトルネックが移ってきます。 そのため、複数台展開を切るとその点で一定の不利を強いられる構造になっていました。逆に言えば複数台をうまく活用できれば8時間の競技ではオンメモリ戦略に十分対抗できるバランスだったかと思います。 この仕様とコード規模に対して、この戦略でベンチマーカーが見つけられるようなバグをほとんど出さずに見事にスコアを上げられたチームは見事と言うほかありません。完敗です。 とはいえ、正攻法ですばやくチューニングを進めていけばちゃんとスコアップが期待できる問題には出来ていたと思いますし、実際そういうチューニングを行って予選を突破したチームが多かったようです。
また、ISUCONのコンセプトは初見のシステムを短期間で良い感じにスピードアップさせることなので、必ずしも自分の知ってるor得意なものが当たるとは限りません。 ISUCONはそういうポイントも含めたWeb技術の総合格闘技的な競技だと僕は考えているので、必ずしも既存のものに合わせた技術選定にはこだわりませんでした。
h2oはkazuhoさんの作った高速なHTTP1/HTTP2サーバーです。今回はHTTP1のフロントサーバー(LB)として採用しました。 昨今のWebサーバーの事情を追っていれば一度はh2oを触ったことがあるだろうし、そうでなくともLBがボトルネックになることは無いと考えていたため、 h2oをちゃんと追っている、あるいは日常的に使っている人にとっては嬉しいし、そうでない人にはnginxなどをイチから構築する能力を要求するということで、 Webサーバー運用という観点でのインフラスキルを問うものとして妥当だと考えて採用しました。
MariaDBは単純にCentOSの標準のyumリポジトリで入るMySQL ServerがMaria DBだからです。募集のタイミングでCentOSを採用する予定であることは明示していたので、 これも下調べをすればMySQL Serverの標準パッケージが最新のCentOSにはないことが分かったはずです。これもやはりOS知識という観点でのインフラスキルを問う要素になっていました。 このMariaDBは5.5なのでMySQL 8などへのアップグレードにもそれなりに知識が要ります。データディレクトリの初期化/アップグレードや必要に応じたパーミッションの修正、my.cnfの設定やそのチューニングにはDBAとしての能力を要求しています。 特に、後述のSwap Out地獄を軽減するためにもMySQLのメモリチューニングは必須でした。また、ロック地獄を低減するために出来るチューニングもいくつかありました。
ちなみに、MySQL 5.7 or 8へのアップグレードはオプティマイザが賢くなるほか、8ではウィンドウ関数がサポートされるので、それを用いてマイページの初期データ生成を楽に行える。などの特徴からMySQL 8は個人的には密かにおすすめの選択肢でした。
この
これに気付くためには、関数/メソッド単位でのプロファイリングも併せて見る必要があります。 死闘の果てにの手法はシンプルながらこれを攻略するのには大変有効なプロファイリング手法だったと思います。
分かってしまえばあとは単に解消するだけなので詳しい解法はここでは省略します。
最後の総合レポートのチェックで行われるレポート作成で大量のSwap Outが発生していることが分かります。 これは、多くのMySQLクライアントライブラリの実装で使われているMySQL Connector C(libmysqlclient)の挙動とも関係があります。 MySQL Connector Cではクエリの結果を読み込むためにmysql_store_resultかmysql_use_resultのどちらかを利用する必要があります。 多くの実装では
レポートの生成ロジックではreservationsテーブルの全てのレコードを参照します。このテーブルには初期データだけでも20万件弱のレコードがあります。
死ぬほどメモリを食うことになることがおわかり頂けるかと思います。最後に一気にSwapが膨らむのが大きなヒントでした。 topやpsでメモリの専有度合いを見てみるとよりはっきりと分かったかもしれません。 これによってSSDとはいえメモリアクセスはやはり遅くなってしまい、MySQLなどがSwapを掴んでしまうとスコアが安定しない要因になります。 また、Swap Outの過程でディスクキャッシュが追い出されるため、やはりそれもパフォーマンス劣化の要因になることがあります。
これを解消するには
サブクエリの
このクエリは参照実装では(ミスでトランザクションの外側にありましたが、これを内側に入れた途端に)ロック競合が増えてロック待ちが一気に増加します。
本来、実際にロックを取らなければならないのは予約しようとしている席のレコード1つだけです。しかし、もとのスキーマではsheetsは共用であり、予約しようとしている席の予約レコードは存在しないレコードです。 つまり、これは存在しないレコードにロックを取る代わりに広範囲のロックで予約を直列化して凌いでいた。というものになります。
そこまで理解すればこれを解決する方法は単純で、空き席をレコードとして予め用意してそれに対してロックを取れるようにすれば良い事がわかります。 もちろんRedisのSet型やList型を利用する手もありますが、空き席のテーブルに対して
ちなみに、これとぶつかるレポートのFOR UPDATEはMySQL(InnoDB)のREPATABLE READにおいて意図的にファントムリードを引き起こす効果がありますが、 レポート処理としては必要性がなく、完全に無駄なコードなのでそれを見抜ければこれは外すことができました。
また、これらを抜けるとキャンセルも詰まりはじめ、さらにそれを改善すると
マニュアルからベンチマークの実行方法を引用します。
最後の行に注目してください。負荷走行中のエラーについてはタイムアウトや500エラーを含む幾つかのエラーについては無視される旨が記載されています。 つまり、バグが残った実装であっても、たまたま問題が起きたケースに当たらずにベンチマークを通過してしまうケースはありえます。
実際の高負荷環境でタイムアウトや500エラーをゼロにするということは殆ど不可能に近いと思います。 特に今回はロックを扱う問題であることから「デッドロックが低確率で発生するが高速」な実装も選択できるようにこのようなルールとなっていました。
チェックする側で言うと、ユーザーは初期データで5000人ぶんが登録されており、これら全ユーザーぶんの状態を全てチェックすることは困難を極めます。 そのため、チェック対象を乱択してチェックを行う実装にせざるを得ませんでした。
その結果として潜在的なバグに気づけなかった場合にランダムfail地獄に陥ってしまっていたかと思います。 点数あがる=試行回数も増えるということになりますので、確率的なものであるためにスコアが上がれば上がるほどFAILしやすくなるということです。
実サービスでもユーザーやオペレータからの問い合わせで発覚するようなバグは同様に再現が難しいことが多く、 実際はバグに気付いたらなるべく早く修正するのが筋ですし、これ自体はISUCONのあり方としては適切かなと思います。
ベンチマーカーから「負荷レベルが上昇しました」「レスポンスが遅いため負荷レベルを上げられませんでした」というメッセージを見たかと思います。 マニュアルにも以下の通り記載がありました。
しかし、負荷レベルそのものについての説明は少々説明不足だったかもしれません。 質問が無かったため問題なかったかもしれませんが念のために改めて説明します。
負荷レベルというのはベンチマーカーの並列度のようなものと考えてもらって差し支えありません。 ISUCONという競技の性質上、参照実装はそれなりに遅い実装になっています。対して、チューンアップするとそれよりも全然速い実装が生まれます。 すると、性能が全然違う実装に対してどのようにベンチマークを実施するかという問題が発生します。
遅い実装に合わせると速い実装に対してベンチマーカー側がサチってスコアの伸びが悪くなってしまいます。 逆に速い実装に合わせると遅い実装でタイムアウトが発生します。 負荷レベルを徐々に上昇させていけば、速い実装にも遅い実装にも適切にベンチマークを掛けることができるというのがその存在理由です。 もちろん、遅い実装に対して負荷レベルを上げすぎては同様の問題が発生するため、エラーやレスポンスタイムでキャップを掛けて一定以下に性能や安定性が落ちなければレベルが上がる。という仕組みになっていました。
負荷レベルが上昇すると並列度が上がるため、アプリケーションはより多くのリクエストを受け取ることになります。 そのため、十分にチューニングされていれば負荷レベルの上昇に伴ってより多くのスコアを稼げていたはずです。
上記の前提を踏まえて、ベンチマークガチャに陥った人は何かしらの理由で負荷レベルの上昇が不安定になっていたと考えられます。 たとえば、ロック競合が解決しきれておらず、ときどきロック待ちがすごく長くなってしまうような実装だと、たまたまロック待ちに掛からなかった回には負荷レベルの上昇が見込めます。 しかし、ロック待ちに掛かった回には負荷レベルが上昇しません。
そのため、十分にロック競合が解決しきらないとベンチマークガチャに陥ってスコアが安定しなくなってしまいます。 それでも予選を突破出来たチームは幸運だったかもしれません。
サーバーのプロビジョニングについては、種VMをAnsibleでセットアップしてそれをもとにディスクイメージを作り各インスタンスを建てるという方法を取ることで実現しました。 (チームごとにサーバーへのログインパスワードが違いましたが、これもGMOさん側でやって頂けました。) もちろん、当日や前日に微調整が入ることはよくある(というかあった)わけですが、それはAnsibleでプロビジョニングすることで差分だけをスムーズに適用できました。
今回の問題が快適に提供できたのは手厚くインフラを整備してくださったGMOさんのおかげです。本当にありがとうございました!
まずはじめに、今回の問題は言語間の公平性にかなり気を揉んで、あまり言語間で差が出にくいように作ったつもりです。 アプリケーションが全てのデータをメモリ上に持つスタイル(いわゆるオンメモリ戦略)で書き換えにくいボリュームと仕様、 ランダムな席選択における純粋な実装でのロック範囲の広さなどのDBネックとなる問題の数々の解決の解決が主です。これらを8時間で全て解消するのは至難の技です。 そのため、ボトルネックを効率よく潰していくチームワークを競うという側面もありました。
Goが圧倒的に有利なのではないかという話は毎回挙がります。 もちろん、ネイティブコードを吐いて実行するGoが中間コードをVMで実行するLLよりCPUやメモリ領域を効率的に使えます。IOストリームの処理も並行プログラミングも得意です。 対して、PerlやRubyなどのLLはロジックをゆるふわに書き換えて試行錯誤したり、メタプログラミングでワークアラウンドを取ったりといった手早い修正が手軽に出来る強みがあります。 ISUCONは制限時間がある競技ですので、その制約の中でどの言語が持つメリットを取るのが有利かはその使い手の力量と問題のボリュームや性質に大きく依存します。
ちなみに、今回の問題でアプリケーションのCPU利用効率がスコアに影響してくるのは(全ての言語でチューニングしたわけではないので一概に言えませんが)だいたい15万スコア以上になってからかと思います。 予選中に出た最高スコアは10万ほどですので、どのチームもDBネックは潰しきれないまま終了したと考えています。ちなみに、今回の予選で最終スコアが最も高かったチームが選択していた言語はPHPでした。
また、型付けという観点では、今回はJSONを扱う機会が多かったため、LLではJSONの型を変更せずに修正を進めるのにはコツが必要だったかと思います。 Goでは構造体が用意されていたので、それに合わせてデータを整形すればなんとかなるため、そういう意味では少し楽ができたかもしれません。
しかし、今回の問題をそれなりに解こうとすると大量のコードの書き換えが発生します。書き換える量が増えれば当然バグを生んでしまうリスクも高まります。 静的な型チェックによる恩恵が多いかと思いきや、WebアプリケーションはIOが多いため、入力を構造体にマッピングする過程で暗黙的に型変換が発生します。 型変換の問題は実行時エラーになるため、コンパイル時に問題を検出しきることはやはり困難で、型の修正は影響範囲が広いためIDEの支援を受けても修正の足取りは少し重くなると思います。 今回の問題はロジックらしいロジックも少なく、ほとんどがDBから受け取ったデータをJSONで返しているだけの処理で、なおさらその比率が高いと言えます。
対して動的型付け言語では、(TypeScriptを除き)静的な型チェックは行なえませんが、前述の通りIOが中心のアプリケーションで静的な型チェックによる恩恵が少ないと考えると、バグを作りこんでしまうリスクはそこまで変わらなかったと考えられます。 むしろ、迅速にトライ・アンド・エラーしたり、動作確認のためにコード片を簡単に動かしたり、メタプログラミングで強引に状態を確認したりできることで、比較的足取り軽く動けるかと思います。
今回の参照実装においては
いろいろ書きましたが、つまるところパフォーマンス面での言語選択の違いは、単純な良し悪しでは語れずパフォーマンス上の問題に対する解決策としての相性でしか語れないということです。 ISUCONに限って言えば、単にその言語の特徴が問題にマッチすればボトルネックを簡単に解消できるというだけの話です。
チューニングコンテストである以上はどうしてもCPUとメモリが絡んでくるため、その点においてGoは比較的有利であることは否定しませんが、 PerlのXSUBやRubyのC Extensionなどでボトルネックとなる部分をネイティブコードで実装することは可能で、実際にネイティブコードで実装されたテンプレートエンジンやWebServerなどは実際の仕事でも常用していることと思います。 そのため、有意な差が出るほどGoがCPU利用率で有利になる場面という場面はそうそうなく、またボトルネックがCPUに変わるまでチューニングする過程で勝負が決するため、Goを選択することが必ずしも有利に働くとは限りません。
ちなみに、ベンチマーカーはなぜGoで書いているのかといえば、HTTPベンチマーカーの性質から並行処理が非常に多くなり、 かつ必ずベンチマーク対象より高速に動くことを要求するためにCPUがボトルネックになるレベルでチューニングするために、Goはその問題解決に適した選択肢のひとつになるからです。 同様の特徴で言えばErlangなどでも良かったわけですが、比較的慣れており過去のISUCONのベンチマーカーでも実績があり、なにより過去のコードを使い回せるのでGoを採用していました。
そういうわけなので、各位なかよくお願いします。
なお、この問題を作るに当たり合宿や事前回答会で問題やベンチマーカーに対してのフィードバックをいただけたことが完成度を高めるために非常に役立ちました。 これらを企画してくださった941さん、フィードバックを頂いたカヤック出題チームのfujiwaraさん、ken39argさん、そして事前回答にご協力頂いたtagomorisさん、gfxさん、arabikiさん、macopyさん、mix3さん、gurisugiさん、改めてありがとうございました! また、言語間移植に協力して頂いたgfxさん、arabikiさん、omegaさん、daisuzuさん、polidogさん、本当に助かりました。ありがとうございました!
今回、DeNAではこちらのメンバーで予選問題を準備しました。
karupanerura (問題作成、ベンチマーカー実装) sonots (ベンチマーカー実装) rkmathi (インフラ、プロビジョニング等) xaicron (ポータル作成)
DeNAではゲームのバックエンドサーバーなど大量のトランザクション/ロックと戦う仕事も数多くあり、プラットフォーム事業では捨てるわけにはいかない大量のデータを扱いながら如何に大規模アプリケーションを高速に保ち安定運用するか、などといった課題が数多くあります。 僕自身も業務内で何度かチューニングする必要性に迫られ、その問題を解決してきました。実際の問題解決とISUCONはやはり違いますが、それでもこれらの課題の解説に興味がある方はぜひDeNA社員に声を掛けてみてください。
以上をもって解説と講評とさせていただきます。ありがとうございました。
予選に参加した皆様、お疲れ様でした。 楽しんで頂けましたでしょうか。
お陰様で大きなトラブルもなく無事に予選を終えることができました。 参加者の皆様をはじめとした皆さんのご協力がなければ成し得ないことでした。 ご協力いただいた皆様、ありがとうございました。
課題アプリケーション
今回の課題はイベントのチケット予約アプリケーションでした。ユーザーを作成、またはログインを行うと座席を予約することができます。 座席は抽選で決まる仕組みになっており、ランダムに決まった座席が即座に分かるようになっています。 埋まっている座席は黒く塗りつぶされ、自分の獲得した座席は緑色の字で表示されています。 また、自分の座席をクリックするとキャンセルを行うことができます。
マイページでは自分の最近予約(orキャンセル)した席を5件、最近予約(orキャンセル)したイベントを5件、そして予約総額を表示していました。 また、未ログイン時は予約/キャンセル/マイページの閲覧はできませんが、座席の空き状況を確認することができました。
管理画面もあります。 管理画面は一般向けの画面とは異なりログインするまでどのような情報も見ることはできません。 ログインすると、一般向けに公開していないものも含めてすべてのイベントを表示できます。 座席の予約状況も同様に閲覧することができるほか、イベントの状態を変更することができます。 イベントの状態は公開/非公開/終了の3パターン存在し、公開/非公開は何回でも変更することができますが、終了にすると二度と状態を変更できません。
そして、管理画面にはレポート機能もあります。 全体/イベント毎のチケットの購買履歴をCSVとしてダウンロードすることができます。
実装としては、フロントエンドはvue.jsを用いたSPA風の構成になっており、ラウンドトリップを減らすため初期レンダリングに利用するデータだけJSONでHTMLに埋め込んで、 あとは基本的にAPI経由でデータを取得するという仕組みになっています。(Instagramなどで行われています)
バックエンドは3台のCentOSのサーバー(2core/1GB)で、初期状態では3台起動して1台だけですべてのリクエストを処理していました。 データベースはCentOS7の標準パッケージのMariaDB 5.5、リクエストはHTTPでtcp/80にh2o 2.2.5で受けて、Perlの参照実装にリバースプロキシして渡していました。
初期データとしては101人の管理者アカウント、18個のイベント、5000人のユーザーアカウント、キャンセルを含む予約データ約20万件が入っていました。
問題のコード群は github.com/isucon/isucon8-qualifyで公開しています。
テーマ
気付いていた方も何人かいらっしゃいましたが実はこの問題はISUCON2の問題のリバイバルです。 ISUCON2ではログイン、マイページ、キャンセル、イベントの公開状態、レポートなどはなく、今回新たに要素として取り入れました。 これによってずっと複雑度が増していて、同様のアプローチでは問題を解決しづらくなっており、これを壊さずにチューニングするのはとても大変だったと思います。今回は実際のWebアプリケーション運用の現場で起きる実際の問題解決に近いものを課題にしたいと考えていました。 具体的には以下のようなポイントを押さえることを目指しました。(事前のディスカッションの議事録から抜粋)
- メモリに乗っけるだけでおしまいの問題にはしない
- 実務でそこまでやる場面はほぼ皆無
- ある程度のCPUバウンドにして複数台でCPU負荷を分散することでスコアアップできる問題にする
- CPUバウンドに寄せすぎない
- (おそらく)Goが無双してしまう
- 実際の言語選択はパフォーマンスだけでない様々な要因で決めることになるし、言語選択が大きく勝敗を分ける問題にはしたくない
- 攻略ポイントとそこに行く道筋がわかる問題にしたい
- ちゃんと計測すれば計測結果とコードから仮説を立てて問題を解決していくヒントが得られる
- 限られたマシンリソースでどう捌くかを考えるようなものにしたい
- スケールアップ/スケールアウトがこれ以上できないほどサービスが成長してしまったとき、しばしばそういう場面に陥る
これらのポイントを押さえるため、レースコンディション問題を題材に大量の並行トランザクション地獄を作ると、自分たちが実際に向き合うことの多い課題に近く良いのではないか? 過去のISUCON2がこれに近かったし過去問のリバイバルというのは新しいし、面白いのではないか?ということでこういう問題になりました。
ということで、今回は一芸では突破できない様々なハードルを用意しましたが、メインテーマは強いて言えば「大量の並行トランザクションによるロック地獄をどう解決するか?」でした。 様々な問題の解決が要求されるので、これを突破できたチームは本当にすごいと思います。おめでとうございます。
参照実装
参照実装の作成では、悪い設計の上でそこそこ読みやすいコードをなるべく愚直に実装しました。具体的には、以下の2つのポイントを意識しました。- 悪いDRY
get_event /
get_events
が万能すぎる
reservations
テーブルが万能すぎる
しかし、開催後に気付いたことですが、参照実装にはいくつかバグが残ってしまっていました。
予約エンドポイントの予約成功するまでの無限ループはキャンセル時刻をテーブルに保存する仕様を入れる前の実装の名残がうっかりそのまま残ってしまったものでした。 また、その歳にトランザクションの範囲も直しそこねていて、それによってレースコンディション問題が低確率で発生するようになっていました。パフォーマンスが上がるとこれがエラーとして出て来るようになってしまったと思います。
Discordの感想部屋で話題になっていた
GROUP BY event_id HAVING MIN(reserved_at) = reserved_atのクエリはMySQLでは結果が不定になります。 これは一見、最初の予約が有効な予約として扱われる用に見えますが、
HAVINGの条件は集計「後」の絞り込みであり、集計後のカラムの値は集計の基となるカラムまたは集計関数を通したカラムでなければ不定となるため、正しい結果となりません。 もともと、これは上記のトランザクションが正常に機能する前提で「最初の予約が有効な予約として扱う」という無駄な防御機構として入れたものだったのですが、トランザクションのミスも相まって結果的にダブルブッキングが可能なようにミスリードできてしまうものとなってしまいました。
また、Go実装においてはレポートの生成処理で消費するメモリ量が、意図せず他言語における実装に対して有意に少ない実装になってしまっていました。 要因は大きく3つあります。
- 他の言語の実装において非破壊ソートを行っていたが、Goでは破壊的なソートで移植してしまっていた
- とはいえ、これは他の言語では非破壊ソートとはいえ実体は参照で扱われるためあまり大きな影響は無い(Goでは直のstruct)
database/sql
のインターフェースで自然にDBを扱った為に他の言語において作っていたSELECT結果の配列を作らずに済んでしまっていた- (上記と関連して)
go-sql-driver/mysql
の実装がMySQL Connector Cベースではない独自のものとなっていることに気付かなかった- MySQLドライバの実装で一般的に利用されるmysql_store_resultで行われるレコードのバッファリングがライブラリ側で行われなかった
database/sqlと
go-sql-driver/mysqlの問題に関しては、事前にこれに気づいていれば
go-sql-driver/mysqlによる実装とあまり差が出ないようにmysql_use_resultやSELECT .. INTO OUTFILE構文を使った参照実装にするなど、なるべく言語選択の差を減らす工夫が出来たかもしれません。 しかし、この問題は基本的に愚直に手続き書いてるコードを移植しただけで起きたことです。他の部分でも(たとえば)HTTPのパスルーティングの計算量などもおそらく言語間の差異はあったかと思います。 つまり、単にこれはその言語やライブラリの持つ性質と言えるので、それを踏まえてどこまで近い条件に揃えるようケアするかという塩梅の問題と言えます。 ただ、そういった側面がある一方でこれは意図して用意したボトルネックの一つではあったので、Goで挑んだ場合は少し難易度が落ちていたことも否定できず、参照実装でそういった部分にここまで差が出てしまうことはあまり良くなかったと考えています。
その他、言語によっては
db/init.shのエラーをハンドルしていないケースがあったり、Go実装ではGetEventsとGetEventの間でトランザクションオブジェクトが渡っていなかったり、Node.js実装では参考に用意したindex.jsのビルドが古かったりなど、細かいバグがいくつか存在しました。
これらの参照実装の不手際で不要な混乱を招いてしまい本当に申し訳ありませんでした。運悪くこれらに躓いてしまったチームもあったと思います。 ただ、競技としては皆さん同じ条件の下で競っていますので、参照実装のバグも込みで時間内に問題を解決できたかどうかが結果ということでご容赦頂ければと思います。
講評
皆さんお疲れ様でした。特に見事予選を突破したチームは本当におめでとうございます。 予選を突破したチームは8時間という短い時間の中でこの問題に対してその成果を残せたということで、それは本当にすごいことだと思います。 とはいえ、スケジュールや体調、環境などの偶然で一定は運の要素も入るし、得意不得意も人それぞれですので、必ずしも予選を通過できなかったチームが予選を通過したチームに劣るということはありません。 惜しくも予選を突破できなかったチームも、ほとんどのチームではかなりの改善が進められていて、本当に惜しかったと思います。さて、皆さんのブログやGithubのコードを軽くざっと眺めさせてもらいました。 最初のボトルネックがうまく特定できたチームとそうでないチームが半々くらいでしょうか。
上位陣のチームはやはり皆さん
get_event地獄を解消しないとどうしようもないことに早々に気づけていたようです。 初動がうまく出来たチームは午前中には5000を超えるスコアを残せてたようでした。 反面、スコアがうまく伸ばせなかったチームは、ボトルネックの特定がうまくできなかったり、あるいはその後の改修のデバッグに手間取ったり、インフラ構成の変更に手間取ったり、 チームの力を発揮しきれずに開発スピードが出せなかったり、などなどのトラブルを時間内にうまく解決出来なかったのかなと思います。
特に、惜しかったチームには改修のバグ修正に手間取ったチームが多かったように見えました。
たとえば、
eventsや
sheetsのキャッシュなどは毎度DBからデータを作っているコードでは破壊的に扱っても問題がないために破壊的に扱われがちです。 しかし、いざキャッシュしようと思うと多くの実装ではキャッシュしたsheetを参照として受け取る実装になりがちで、それを破壊的に扱っている部分がバグにつながりやすい構造になっていました。 キャッシュは簡単なようで扱いが難しくその上に途中で辞めることが難しいため「キャッシュは麻薬」という言葉もあるほどですが、上記のような問題をさっと見抜けないと今回の問題もキャッシュの適用は困難だったと思われます。 これはあくまでも一例で、ロックを甘くしたことによって起きるレースコンディション問題など、バグを生みやすい要素が多々ある問題になっていた為、ほとんどのチームがバグに遭ってそれを修正を試みる(あるいはrevertする)といった問題を踏んでいました。
こういった問題をすばやく解決するためにはデバッグ(QA)能力も重要です。 少なくとも1分以上は掛かってしまうベンチマークをわざわざ待たずに、デバッガを仕込んだり変数ダンプなどでデバッグを手早く行っていくという能力も重要な要素でした。 勝ち抜いたチームはバグで躓くことはありつつも、ある程度しっかりとバグを取ることができていたようです。
さすがに競技中にテストを書くチームはなかったようですが、予約→取得→キャンセル→取得といった流れくらいはシュッとテストできるようにしておくと開発スピードが上がったかもしれません。 ほうじ茶ラテ部はcurlなどでシュッと動作確認出来るようにしておいたようです。これは良いプラクティスだと思います。
また、チームによっては複数台展開を切ってほとんどメモリに載せてレスポンスをさばく戦略を取ったチームもあったようです。 さらに、この問題は(結果的に時間内にDBネックを脱出しきったチームは殆ど無かったようですが)DBネックを解消しきるとアプリケーションのCPUにボトルネックが移ってきます。 そのため、複数台展開を切るとその点で一定の不利を強いられる構造になっていました。逆に言えば複数台をうまく活用できれば8時間の競技ではオンメモリ戦略に十分対抗できるバランスだったかと思います。 この仕様とコード規模に対して、この戦略でベンチマーカーが見つけられるようなバグをほとんど出さずに見事にスコアを上げられたチームは見事と言うほかありません。完敗です。 とはいえ、正攻法ですばやくチューニングを進めていけばちゃんとスコアップが期待できる問題には出来ていたと思いますし、実際そういうチューニングを行って予選を突破したチームが多かったようです。
h2oとMariaDB
h2oやMariaDBでハマったり面食らった方も多かったようです。特にMaria DBはsystemd上も mariadb.service なので知らないと混乱したかと思います。 例年の選択を考えると少し不思議に見えるかもしれませんが、これらはそこまで変な選択ではないと考えています。また、ISUCONのコンセプトは初見のシステムを短期間で良い感じにスピードアップさせることなので、必ずしも自分の知ってるor得意なものが当たるとは限りません。 ISUCONはそういうポイントも含めたWeb技術の総合格闘技的な競技だと僕は考えているので、必ずしも既存のものに合わせた技術選定にはこだわりませんでした。
h2oはkazuhoさんの作った高速なHTTP1/HTTP2サーバーです。今回はHTTP1のフロントサーバー(LB)として採用しました。 昨今のWebサーバーの事情を追っていれば一度はh2oを触ったことがあるだろうし、そうでなくともLBがボトルネックになることは無いと考えていたため、 h2oをちゃんと追っている、あるいは日常的に使っている人にとっては嬉しいし、そうでない人にはnginxなどをイチから構築する能力を要求するということで、 Webサーバー運用という観点でのインフラスキルを問うものとして妥当だと考えて採用しました。
MariaDBは単純にCentOSの標準のyumリポジトリで入るMySQL ServerがMaria DBだからです。募集のタイミングでCentOSを採用する予定であることは明示していたので、 これも下調べをすればMySQL Serverの標準パッケージが最新のCentOSにはないことが分かったはずです。これもやはりOS知識という観点でのインフラスキルを問う要素になっていました。 このMariaDBは5.5なのでMySQL 8などへのアップグレードにもそれなりに知識が要ります。データディレクトリの初期化/アップグレードや必要に応じたパーミッションの修正、my.cnfの設定やそのチューニングにはDBAとしての能力を要求しています。 特に、後述のSwap Out地獄を軽減するためにもMySQLのメモリチューニングは必須でした。また、ロック地獄を低減するために出来るチューニングもいくつかありました。
ちなみに、MySQL 5.7 or 8へのアップグレードはオプティマイザが賢くなるほか、8ではウィンドウ関数がサポートされるので、それを用いてマイページの初期データ生成を楽に行える。などの特徴からMySQL 8は個人的には密かにおすすめの選択肢でした。
get_event地獄
get_eventの実装はイベントIDに対して全席ぶんのステータスを含めてイベントのすべての状態を返す実装になっていました。 すべてのシート(1000個)に対して都度クエリを発行するN+1問題になっているなど、かなり非効率的な処理をしています。
この
get_eventがアプリケーションのあらゆる箇所で呼び出されていました。曖昧な命名による悪いDRYの典型です。 さらに
get_eventsの実装では
get_eventを対象のイベントIDごとに呼び出しています。 そのため、
get_eventは
GET /や
GET /api/events/{id} などのボトルネックになるほか、構造的に全体的なパフォーマンスを劣化させる要因になっていました。これに気付くためには、関数/メソッド単位でのプロファイリングも併せて見る必要があります。 死闘の果てにの手法はシンプルながらこれを攻略するのには大変有効なプロファイリング手法だったと思います。
分かってしまえばあとは単に解消するだけなので詳しい解法はここでは省略します。
Swap Out地獄
最初にベンチマークを走らせるとPerl実装では500MBほどの大量のSwap Outが発生することに気付くかと思います。dstatで見るとこんな感じになります。
[isucon@XX-XX-XX-XX ~]$ nice -n 19 dstat -tc -C 0,1 -lmdrns 10
----system---- -------cpu0-usage--------------cpu1-usage------ ---load-avg--- ------memory-usage----- -dsk/total- --io/total- -net/total- ----swap---
time |usr sys idl wai hiq siq:usr sys idl wai hiq siq| 1m 5m 15m | used buff cach free| read writ| read writ| recv send| used free
22-09 23:54:47| 3 2 95 0 0 0: 2 1 96 0 0 0|0.23 0.18 0.07| 296M 22.7M 318M 356M|3191k 63k| 133 5.16 | 0 0 | 0 2048M
22-09 23:54:57| 13 1 85 0 0 0: 26 3 69 1 0 1|0.27 0.19 0.08| 378M 23.0M 336M 255M| 729k 6705k|7.50 41.1 |1675B 42k| 0 2048M
22-09 23:55:07| 3 1 96 0 0 0: 82 11 4 0 0 4|0.46 0.23 0.09| 398M 23.0M 336M 236M|1638B 87k|0.10 3.50 |2467B 11k| 0 2048M
22-09 23:55:17| 58 8 32 0 0 2: 77 10 10 0 0 3|0.95 0.34 0.13| 436M 23.0M 336M 197M| 0 312k| 0 9.10 |6927B 510k| 0 2048M
22-09 23:55:27| 88 10 0 0 0 3: 85 11 0 0 0 3|1.72 0.53 0.19| 523M 23.1M 336M 110M| 0 124k| 0 8.30 |3850B 375k| 0 2048M
22-09 23:55:37| 86 10 0 0 0 4: 85 11 0 0 0 4|2.76 0.79 0.28| 525M 23.1M 336M 108M| 0 123k| 0 9.20 |4534B 184k| 0 2048M
22-09 23:55:47| 85 11 0 0 0 4: 86 10 0 0 0 4|3.49 1.01 0.36| 528M 23.1M 336M 105M| 0 132k| 0 9.90 |6307B 447k| 0 2048M
22-09 23:55:57| 86 11 0 0 0 3: 85 12 0 0 0 3|4.03 1.21 0.43| 668M 9.88M 151M 164M| 153k 29M|10.3 71.9 |2063B 129k| 72k 2048M
22-09 23:56:07| 58 11 30 1 0 1: 32 15 51 1 0 1|3.92 1.28 0.46| 857M 136k 14.4M 121M| 98M 87M| 546 329 |2881B 1221k| 557M 1491M <-- report!!
最後の総合レポートのチェックで行われるレポート作成で大量のSwap Outが発生していることが分かります。 これは、多くのMySQLクライアントライブラリの実装で使われているMySQL Connector C(libmysqlclient)の挙動とも関係があります。 MySQL Connector Cではクエリの結果を読み込むためにmysql_store_resultかmysql_use_resultのどちらかを利用する必要があります。 多くの実装では
mysql_store_resultがデフォルトで使われるようになっています。パフォーマンス面での主な違いは前者が全ての結果を一度にMySQLから受け取るのに対して、後者は1レコードづつ受信する点です。(詳しくはMySQLの公式ドキュメントを参照してください)
レポートの生成ロジックではreservationsテーブルの全てのレコードを参照します。このテーブルには初期データだけでも20万件弱のレコードがあります。
mysql_store_resultを用いた実装では、MySQL Connector Cが20万件ぶんのデータをMySQLから受け取ってメモリ上に展開することになります。 さらに、今度はそのデータを各言語のデータ構造に変換し、もとのデータが解放されるまではこれでざっくり2倍です。そして price などを計算して整形したデータを作って、これでざっくり3倍です。 おまけにそのデータに対して非破壊ソートを行います。最後にCSVの文字列データをメモリ上で作って、ざっくり4倍です。
死ぬほどメモリを食うことになることがおわかり頂けるかと思います。最後に一気にSwapが膨らむのが大きなヒントでした。 topやpsでメモリの専有度合いを見てみるとよりはっきりと分かったかもしれません。 これによってSSDとはいえメモリアクセスはやはり遅くなってしまい、MySQLなどがSwapを掴んでしまうとスコアが安定しない要因になります。 また、Swap Outの過程でディスクキャッシュが追い出されるため、やはりそれもパフォーマンス劣化の要因になることがあります。
これを解消するには
mysql_use_resultやSELECT .. INTO OUTFILE構文を使うと良いでしょう。 またレスポンスを返す際にもレコード毎にWriteすることでアプリケーションの消費メモリ量はかなり抑えることができます。ファイルに書き出す場合はsendfileシステムコールを使うという手段もあるでしょう。 ファイルを作る際にファイルシステムのキャッシュを消費することも考えると
mysql_use_resultのほうが効率は良かったかもしれません。
席の乱択とロック地獄
参照実装では予約時の席の乱択はこのような実装になっていました。
SELECT * FROM sheets WHERE id NOT IN (SELECT sheet_id FROM reservations WHERE event_id = ? AND canceled_at IS NULL FOR UPDATE) AND `rank` = ? ORDER BY RAND() LIMIT 1
サブクエリの
reservationsテーブルへのSELECTはインデックスではevent_idぶんの絞り込みしか行えず、さらに
FOR UPDATEが付いています。 ちなみに、キャンセルが速くならないうちは event_id で絞り込めていればそれなりのレコード数まで減らせた為、
event_idと
canceled_atに対してインデックスを貼ることでそれだけでも一定の高速化はできます。
このクエリは参照実装では(ミスでトランザクションの外側にありましたが、これを内側に入れた途端に)ロック競合が増えてロック待ちが一気に増加します。
本来、実際にロックを取らなければならないのは予約しようとしている席のレコード1つだけです。しかし、もとのスキーマではsheetsは共用であり、予約しようとしている席の予約レコードは存在しないレコードです。 つまり、これは存在しないレコードにロックを取る代わりに広範囲のロックで予約を直列化して凌いでいた。というものになります。
そこまで理解すればこれを解決する方法は単純で、空き席をレコードとして予め用意してそれに対してロックを取れるようにすれば良い事がわかります。 もちろんRedisのSet型やList型を利用する手もありますが、空き席のテーブルに対して
ORDER BY RAND() LIMIT 1 FOR UPDATEなどとするだけでも十分なスコアアップは狙えたかと思います。 MySQL8では
FOR UPDATE SKIP LOCKEDが使えるので、ランダムな順番(ord)を予め振っておいて
ORDER BY ord LIMIT 1 FOR UPDATE SKIP LOCKEDなどとする手もありました。
ちなみに、これとぶつかるレポートのFOR UPDATEはMySQL(InnoDB)のREPATABLE READにおいて意図的にファントムリードを引き起こす効果がありますが、 レポート処理としては必要性がなく、完全に無駄なコードなのでそれを見抜ければこれは外すことができました。
また、これらを抜けるとキャンセルも詰まりはじめ、さらにそれを改善すると
reservationsテーブルへのINSERTが詰まりはじめます。 これはMySQLで
innodb_autoinc_lock_mode = 2などを設定したりその他のロックや書き込み周りの設定調整をすることで一定の改善が見込めます。
ランダムfail地獄
ランダムfail地獄に苦しんだ方もいらっしゃるようでした。 これはベンチマークと問題の性質から起きてしまう問題です。マニュアルからベンチマークの実行方法を引用します。
ベンチマーク走行は以下のように実施されます。
初期化処理の実行GET /initialize(10秒以内)
アプリケーション互換性チェックの走行 (適宜: 数秒〜数十秒)
負荷走行 (60秒 - 2.の互換性チェックにかかった時間)
負荷走行後の確認 (適宜: 数秒〜数十秒)
各ステップで失敗が見付かった場合にはその時点で停止します。 ただし、負荷走行中のエラーについては、タイムアウトや500エラーを含む幾つかのエラーについては無視され、ベンチマーク走行が継続します。
最後の行に注目してください。負荷走行中のエラーについてはタイムアウトや500エラーを含む幾つかのエラーについては無視される旨が記載されています。 つまり、バグが残った実装であっても、たまたま問題が起きたケースに当たらずにベンチマークを通過してしまうケースはありえます。
実際の高負荷環境でタイムアウトや500エラーをゼロにするということは殆ど不可能に近いと思います。 特に今回はロックを扱う問題であることから「デッドロックが低確率で発生するが高速」な実装も選択できるようにこのようなルールとなっていました。
チェックする側で言うと、ユーザーは初期データで5000人ぶんが登録されており、これら全ユーザーぶんの状態を全てチェックすることは困難を極めます。 そのため、チェック対象を乱択してチェックを行う実装にせざるを得ませんでした。
その結果として潜在的なバグに気づけなかった場合にランダムfail地獄に陥ってしまっていたかと思います。 点数あがる=試行回数も増えるということになりますので、確率的なものであるためにスコアが上がれば上がるほどFAILしやすくなるということです。
実サービスでもユーザーやオペレータからの問い合わせで発覚するようなバグは同様に再現が難しいことが多く、 実際はバグに気付いたらなるべく早く修正するのが筋ですし、これ自体はISUCONのあり方としては適切かなと思います。
ベンチマークガチャ
皆さんスコアがベンチマークを回すごとに大きく変わり、まるでガチャのようで苦しんだとおっしゃる方が多かったですがその理由を解説します。ベンチマーカーから「負荷レベルが上昇しました」「レスポンスが遅いため負荷レベルを上げられませんでした」というメッセージを見たかと思います。 マニュアルにも以下の通り記載がありました。
負荷走行中は、毎秒負荷レベルが増えていきます。 ただし、過去5秒以内に何らかのエラーが発生していた場合は負荷レベルが上昇しません。 終了時の負荷レベルや、負荷レベルが上がらない原因になったエラーについてはポータルサイトから確認することができます。
しかし、負荷レベルそのものについての説明は少々説明不足だったかもしれません。 質問が無かったため問題なかったかもしれませんが念のために改めて説明します。
負荷レベルというのはベンチマーカーの並列度のようなものと考えてもらって差し支えありません。 ISUCONという競技の性質上、参照実装はそれなりに遅い実装になっています。対して、チューンアップするとそれよりも全然速い実装が生まれます。 すると、性能が全然違う実装に対してどのようにベンチマークを実施するかという問題が発生します。
遅い実装に合わせると速い実装に対してベンチマーカー側がサチってスコアの伸びが悪くなってしまいます。 逆に速い実装に合わせると遅い実装でタイムアウトが発生します。 負荷レベルを徐々に上昇させていけば、速い実装にも遅い実装にも適切にベンチマークを掛けることができるというのがその存在理由です。 もちろん、遅い実装に対して負荷レベルを上げすぎては同様の問題が発生するため、エラーやレスポンスタイムでキャップを掛けて一定以下に性能や安定性が落ちなければレベルが上がる。という仕組みになっていました。
負荷レベルが上昇すると並列度が上がるため、アプリケーションはより多くのリクエストを受け取ることになります。 そのため、十分にチューニングされていれば負荷レベルの上昇に伴ってより多くのスコアを稼げていたはずです。
上記の前提を踏まえて、ベンチマークガチャに陥った人は何かしらの理由で負荷レベルの上昇が不安定になっていたと考えられます。 たとえば、ロック競合が解決しきれておらず、ときどきロック待ちがすごく長くなってしまうような実装だと、たまたまロック待ちに掛からなかった回には負荷レベルの上昇が見込めます。 しかし、ロック待ちに掛かった回には負荷レベルが上昇しません。
そのため、十分にロック競合が解決しきらないとベンチマークガチャに陥ってスコアが安定しなくなってしまいます。 それでも予選を突破出来たチームは幸運だったかもしれません。
ポータルやサーバーについて
xaicron先生が一晩(一晩ではない)でやってくれました!超スピードでみるみる完成していって迫力がありすごかったです。 ベンチが一瞬だったのはGMOさんのご協力がすごく手厚くて、数チームにつき1台のベンチマークサーバーを用意できたからです。 (本当はVM自体は各チーム1つ用意していたのですがベンチマーク結果への影響を最小限にするために並行で稼働する数を抑えていました。それでも爆速だったと思います。)サーバーのプロビジョニングについては、種VMをAnsibleでセットアップしてそれをもとにディスクイメージを作り各インスタンスを建てるという方法を取ることで実現しました。 (チームごとにサーバーへのログインパスワードが違いましたが、これもGMOさん側でやって頂けました。) もちろん、当日や前日に微調整が入ることはよくある(というかあった)わけですが、それはAnsibleでプロビジョニングすることで差分だけをスムーズに適用できました。
今回の問題が快適に提供できたのは手厚くインフラを整備してくださったGMOさんのおかげです。本当にありがとうございました!
言語間の公平性、あるいはGoは本当に有利だったのかという話
この話は個人的にブログに書くだけに留めようか迷いましたが、こういう議論を野放しにして変な言説が広まっても良くないと思ったため、あえて講評に含めました。まずはじめに、今回の問題は言語間の公平性にかなり気を揉んで、あまり言語間で差が出にくいように作ったつもりです。 アプリケーションが全てのデータをメモリ上に持つスタイル(いわゆるオンメモリ戦略)で書き換えにくいボリュームと仕様、 ランダムな席選択における純粋な実装でのロック範囲の広さなどのDBネックとなる問題の数々の解決の解決が主です。これらを8時間で全て解消するのは至難の技です。 そのため、ボトルネックを効率よく潰していくチームワークを競うという側面もありました。
Goが圧倒的に有利なのではないかという話は毎回挙がります。 もちろん、ネイティブコードを吐いて実行するGoが中間コードをVMで実行するLLよりCPUやメモリ領域を効率的に使えます。IOストリームの処理も並行プログラミングも得意です。 対して、PerlやRubyなどのLLはロジックをゆるふわに書き換えて試行錯誤したり、メタプログラミングでワークアラウンドを取ったりといった手早い修正が手軽に出来る強みがあります。 ISUCONは制限時間がある競技ですので、その制約の中でどの言語が持つメリットを取るのが有利かはその使い手の力量と問題のボリュームや性質に大きく依存します。
ちなみに、今回の問題でアプリケーションのCPU利用効率がスコアに影響してくるのは(全ての言語でチューニングしたわけではないので一概に言えませんが)だいたい15万スコア以上になってからかと思います。 予選中に出た最高スコアは10万ほどですので、どのチームもDBネックは潰しきれないまま終了したと考えています。ちなみに、今回の予選で最終スコアが最も高かったチームが選択していた言語はPHPでした。
また、型付けという観点では、今回はJSONを扱う機会が多かったため、LLではJSONの型を変更せずに修正を進めるのにはコツが必要だったかと思います。 Goでは構造体が用意されていたので、それに合わせてデータを整形すればなんとかなるため、そういう意味では少し楽ができたかもしれません。
しかし、今回の問題をそれなりに解こうとすると大量のコードの書き換えが発生します。書き換える量が増えれば当然バグを生んでしまうリスクも高まります。 静的な型チェックによる恩恵が多いかと思いきや、WebアプリケーションはIOが多いため、入力を構造体にマッピングする過程で暗黙的に型変換が発生します。 型変換の問題は実行時エラーになるため、コンパイル時に問題を検出しきることはやはり困難で、型の修正は影響範囲が広いためIDEの支援を受けても修正の足取りは少し重くなると思います。 今回の問題はロジックらしいロジックも少なく、ほとんどがDBから受け取ったデータをJSONで返しているだけの処理で、なおさらその比率が高いと言えます。
対して動的型付け言語では、(TypeScriptを除き)静的な型チェックは行なえませんが、前述の通りIOが中心のアプリケーションで静的な型チェックによる恩恵が少ないと考えると、バグを作りこんでしまうリスクはそこまで変わらなかったと考えられます。 むしろ、迅速にトライ・アンド・エラーしたり、動作確認のためにコード片を簡単に動かしたり、メタプログラミングで強引に状態を確認したりできることで、比較的足取り軽く動けるかと思います。
今回の参照実装においては
go-sql-driver/mysqlの性質によってGoが少々有利になってしまったことは否定しませんが、 それによってGoが他の言語と比べて圧倒的に有利になったかというと、そうとまでは言えないと考えています。 今回はたまたまレポート生成部分でGoに有利な方向にこの特徴が働きましたが、他の点においてはたとえば並行プログラミングが得意な部分もほとんど活きる部分が無かったかと思います。 実際のところ自前でgoroutineを管理する機会があったチームはなかったのではないでしょうか。 また、他の問題においては必ずしも不利にならないとは限りません。たとえば、ISUCON6の予選問題では参照実装に正規表現が使われており、Goの正規表現エンジンの速度では他の言語と比較して不利な状況でした。
いろいろ書きましたが、つまるところパフォーマンス面での言語選択の違いは、単純な良し悪しでは語れずパフォーマンス上の問題に対する解決策としての相性でしか語れないということです。 ISUCONに限って言えば、単にその言語の特徴が問題にマッチすればボトルネックを簡単に解消できるというだけの話です。
チューニングコンテストである以上はどうしてもCPUとメモリが絡んでくるため、その点においてGoは比較的有利であることは否定しませんが、 PerlのXSUBやRubyのC Extensionなどでボトルネックとなる部分をネイティブコードで実装することは可能で、実際にネイティブコードで実装されたテンプレートエンジンやWebServerなどは実際の仕事でも常用していることと思います。 そのため、有意な差が出るほどGoがCPU利用率で有利になる場面という場面はそうそうなく、またボトルネックがCPUに変わるまでチューニングする過程で勝負が決するため、Goを選択することが必ずしも有利に働くとは限りません。
ちなみに、ベンチマーカーはなぜGoで書いているのかといえば、HTTPベンチマーカーの性質から並行処理が非常に多くなり、 かつ必ずベンチマーク対象より高速に動くことを要求するためにCPUがボトルネックになるレベルでチューニングするために、Goはその問題解決に適した選択肢のひとつになるからです。 同様の特徴で言えばErlangなどでも良かったわけですが、比較的慣れており過去のISUCONのベンチマーカーでも実績があり、なにより過去のコードを使い回せるのでGoを採用していました。
そういうわけなので、各位なかよくお願いします。
まとめ
課題アプリケーションやそれをチューニングする過程で起きる問題、そしてそれを皆さんがどのように解決していったかについて解説しました。 この問題を通じて、実際のアプリケーションのパフォーマンス改善と同じように地に足つけてデバッグしながらチューニングを進めていく重要さと難しさ、そしてそれを解決できたときの楽しさを感じてもらえていたら良かったなと思います。なお、この問題を作るに当たり合宿や事前回答会で問題やベンチマーカーに対してのフィードバックをいただけたことが完成度を高めるために非常に役立ちました。 これらを企画してくださった941さん、フィードバックを頂いたカヤック出題チームのfujiwaraさん、ken39argさん、そして事前回答にご協力頂いたtagomorisさん、gfxさん、arabikiさん、macopyさん、mix3さん、gurisugiさん、改めてありがとうございました! また、言語間移植に協力して頂いたgfxさん、arabikiさん、omegaさん、daisuzuさん、polidogさん、本当に助かりました。ありがとうございました!
今回、DeNAではこちらのメンバーで予選問題を準備しました。
DeNAではゲームのバックエンドサーバーなど大量のトランザクション/ロックと戦う仕事も数多くあり、プラットフォーム事業では捨てるわけにはいかない大量のデータを扱いながら如何に大規模アプリケーションを高速に保ち安定運用するか、などといった課題が数多くあります。 僕自身も業務内で何度かチューニングする必要性に迫られ、その問題を解決してきました。実際の問題解決とISUCONはやはり違いますが、それでもこれらの課題の解説に興味がある方はぜひDeNA社員に声を掛けてみてください。
以上をもって解説と講評とさせていただきます。ありがとうございました。
